Mach, Signal, and Threads

Man is born free, and everywhere he is in chains. - Jean-Jacques Rousseau; The Social Contract
Search for the truth is the noblest occupation of man; its publication is a duty. - Anne Louise Germaine de Staël; De l'Allemagne
Preamble
An operating system is a set of system software that acts as a bridge between the application software and the underlying hardware. Among the various software packaged with an operating system consists of kernel; a program which is responsible for communicating with the hardware and operating the system in its entirety. The purpose of this blog is to explore XNU implementation, understand execution primitives of Mach, and try to understand how event-driven programming takes place.
Mach
Mach is a microkernel initially released in 1985. Since then, it has been incorporated on many Operating Systems such as GNU Hurd and Apple's XNU (see [XNU_GIT]). XNU is a kernel used by Darwin Operating System which is used in macOS and iOS operating systems. One of the major difference between the Mach kernel and Linux is the fact that various kernel subsystems can be modularized. Although the definition of a monolithic and a microkernel is mostly theoretical (see [MICRO_MONO_KERN]) while most production grade kernels have started to converge the properties of both monolithic and microkernel architecture into their implementation, there are still subtle differences between Mach and monolithic kernels such as Linux.
The aim of Mach kernel was to allow Operating Systems to be built on top of Mach. As with microkernel architecture, Mach only provides a smaller subset yet fundamental functionalities such as memory management, CPU scheduling, and inter-process communication. Do note that it is the BSD layer which is responsible for providing interfaces common in Operating Systems. Figure 1 shows the OSX architecture which is an excerpt from Wikipedia: Architecture of macOS.

Mach Taxonomy
The section Mach Kernel Abstractions of [DEV_APPLE_MACH] briefly lays out the various abstractions offered by the Mach Kernel. In XNU, the structure of the said abstractions can be located. A quick browse of XNU source tree shows that there are various files and directories. Explaining all of the source is not the scope of this blog (see [MOSX_INTERNALS] and [OS_INTERNALS]), but we will try and locate the Mach-specific components of our interest. It should be known that [osfmk/] directory contains the componenets of the Mach kernel. Also, [bsd/] contains the BSD kernel components (see [BSD_ON_MACH]). Below gives the respective structure definitions of the various abstractions introduced by Mach:
-
Mach Tasks [osfmk/kern/task.h]. A container that contains various resources required for a "process". Essential resources include: virtual address space (
vm_map_t __ptrauth(...) map;) (see [XNU_PTRAUTH_SIGNED_PTR]), list of Mach threads (queue_head_t threads;), IPC space (struct ipc_port ...;), and also BSD info (struct proc_ro *bsd_info_ro;). Do note that the mentioned attributes alone does not constitute a Mach task and there exists much more attributes. -
Machine Independent Mach Threads [osfmk/kern/thread.h]. A kernel thread. It contains attributes such as Mach task (
struct task *t_task;), read-only thread zone (struct thread_ro *t_tro;), Asynchronous System Trap (AST) pending for the thread (ast_t volatile _Atomic ast;) (see [AST_ENUM_OPT_DECL]), current kernel stack (vm_offset_t kernel_stack;), machine-dependent thread state (struct machine_thread machine;), and other attributes.dangerOn Figure 7-10 of [MOSX_INTERNALS], the definition of
struct threadis shown. At the end, there is one field declared as:struct thread {
...
#ifdef MACH_BSD
void *uthread; // per-thread user structure
#endif
};However, the structure definition has changed since then. Until commit [
e6231be], theuthreadfield was present instruct thread. However, starting from commit [e777678], there no longer exists a distinctuthreadfield inside the structure.A Mach thread also has a 1:1 relation with the user thread. This means that a user thread is associated with only one Mach thread. Upon looking at the
thread_create_internalfunction located in [osfmk/kern/thread.c], we see a line as:static kern_return_t
thread_create_internal (
task_t parent_task,
integer_t priority,
thread_continue_t continuation,
void *parameter,
thread_create_internal_options_t options,
thread_t *out_thread)
{
thread_t new_thread;
struct thread_ro tro_tpl = { };
...
/*
* Allocate a thread and initialize static fields
*/
new_thread = zalloc_flags(thread_zone, Z_WAITOK | Z_NOFAIL);
...
#ifdef MACH_BSD
uthread_init(parent_task, get_bsdthread_info(new_thread),
&tro_tpl, (options & (TH_OPTION_WORKQ | TH_OPTION_AIO_WORKQ)) != 0);
if (!task_is_a_corpse(parent_task)) {
/*
* uthread_init will set tro_cred (with a +1)
* and tro_proc for live tasks.
*/
assert(tro_tpl.tro_cred && tro_tpl.tro_proc);
}
#endif
...
}and (although not exactly required) the function
uthread_init(in [bsd/kern/kern_fork.c]) has the signature as:void uthread_init (task_t task, uthread_t uth, thread_ro_t tro_tpl, int workq_thread);Before I explain how the user thread structure is accessed from the Mach thread, let's see the type definition of
thread_tanduthread_t. On [osfmk/mach/mach_types.h], we see the two type definitions:...
#if KERNEL
/*
* If we are in the kernel, then pick up the kernel definitions for
* the basic mach types.
*/
...
typedef struct thread *thread_t, *thread_act_t, *thread_inspect_t, *thread_read_t;
...
#endif /* KERNEL */
...
/*
* If we are not in the kernel, then these will all be represented by
* ports at user-space.
*/
...
typedef mach_port_t thread_t;
...and since we're looking at the kernel implementation, it will indeed use the
struct threaddefinition forthread_t.For
uthread_t, it is type defined wherestruct uthreadis defined: [bsd/sys/user.h].typedef struct uthread * uthread_t;We'll explore the attributes of
struct uthreadlater. For now, let's inspect theget_bsdthread_infofunction which apparently takesthread_tas its argument and returns a pointer tostruct uthread. It is defined in [osfmk/kern/bsd_kern.c] as:struct uthread *
get_bsdthread_info(thread_t th)
{
return (struct uthread *)((uintptr_t)th + sizeof(struct thread));
}Notice that there is an offset of
sizeof(struct thread)applied to the pointer tostruct thread(which is essentially whatthis above). This would mean that a Mach thread structure is immediately followed by the corresponding user thread structure, in terms of addressing. Consequently, this function returns an address which lies just outside ofstruct threadand does an explicit cast tostruct uthread *.The reader should also be aware that previous commit of this file shows a different variation of
get_bsdthread_infofunction. Instead of doing pointer arithmetic to fetch the address to theuthreadstructure, it would simply return theuthreadfield that was present instruct threaditself. -
Machine Depenedent Mach Threads [osfmk/arm/thread.h] and [osfmk/i386/thread.h]. As seen in the comment in the source, this structure (for "historical reason") is also referred to as the Process Control Block (PCB) in the i386 structure definition. I'll discuss the ARM variant here. As seen in the machine independent structure above, it embeds the machine-dependent thread structure, containing attributes such as user context (
arm_context_t *contextData;) (see [MD_THREAD_CTX]), current per-CPU data (struct cpu_data *CpuDatap;), and plenty of reserved fields. -
BSD process [bsd/sys/proc_internal.h]. Earlier on Mach Tasks, we saw that a reference to BSD info is embedded within the structure (
bsd_info_ro). I should make the reader aware that it's the read-only data associated to a task and/or process, (see [bsd/sys/proc_ro.h]). The comment above the structure definition states that the lifetime of the read-only process structure is 1:1 with that of aproc_t(which is type definition of this structure) or atask_t(again, type definition of Mach task structure). Moreover, it also states that theproc_tandtask_tstructures point to the samestruct proc_rostructure, except for corpses. This structure contains attributes such as parent process ID (pid_t p_ppid;), process group ID (pid_t p_pgrpid;), various UNIX identifiers including user ID, group ID, real user ID, real group ID, session ID, list of processes in process group (LIST_ENTRY(proc) p_pglist;) (see [LIST_ENTRY]), open file structures (struct filedesc p_fd;), actions for signals (struct sigacts p_sigacts;) (see [PROC_SIGACTS]), and other attributes. -
User Threads [bsd/sys/user.h]. It is the BSD per-thread user structure. It contains various attributes, some being related to system calls (
uint64_t uu_args[8];andint uu_rval[2]), continuation attributes for some system calls, signals pending for the thread (sigset_t uu_siglist;), signal mask for the thread (sigset_t uu_sigmask;), list of user threads in [BSD] process (TAILQ_ENTRY(uthread) uu_list;) (see [TAILQ_ENTRY]), exit reason (struct os_reason *uu_exit_reason;), and other attributes. -
IPC Ports [osfmk/ipc/ipc_port.h].
-
Processor Set [osfmk/kern/processor.h]. Mach divides the available processors on a system into one or more processor sets. It is a logical grouping of processors.
cautionSection 7.2.2 of [MOSX_INTERNALS] describes the purpose of Processor Set as:
The original motivation behind processor sets was to group processors to allocate them to specific system activities--a coarse-grained allocation. Moreover, in early versions of Mac OS X, processor sets had associated scheduling policies and attributes, which provided a uniform control of the scheduling aspects of the threads in the set.
When the kernel starts up, a default processor set (
pset0on XNU) is initialized. Except for the default processor set, a processor set may contain zero processor. The default processor set must contain at least one processor. Furthermore, a processor must belong to atmost one processor set at a time.Under Processor Management of Chapter 9 (Volume 2) of [OS_INTERNALS], the following remark could be found regarding processor set:
Recall, that Mach allows for multiple processor sets (and processor nodes), which allows to quickly and easily scale up to Non-Uniform Memory Access (NUMA) and other distributed processing architectures. Apple, however, has neutered this in XNU, relying only on the single
pset0- returned by themach_hostsubsystem'sprocessor_set_default()Mach Interface Generator (MIG) routine. There are, at the time of writing, hints that this may finally change - at least in iOS, wherein the A-series processor's cores are asymmetric ("P"erformance cores and "E"fficiency cores), and could thus greatly benefit from a multi-set configuration.A more brief introduction on asymmetric as well as heterogeneous computing (which uses the notion of P and E cores described above; terminology commonly found in intel implementation) is given below (see [CORE]). Nevertheless, we notice that there is only one processor set object on the system;
pset0.Figure 7-2 of [MOSX_INTERNALS] has the following definition of structure
processor_set:// osfmk/kern/processor.h
struct processor_set {
queue_head_t idle_queue; // queue of idle processors
int idle_count; // how many idle processors?
queue_head_t active_queue; // queue of active processors
queue_head_t processors; // queue of all processors
...
};
extern struct processor_set default_set;On the current implementation, there does not exist explicit attribute on processor set object which references to the processor object.
-
Processor [osfmk/kern/processor.h]. A processor object is a logical representation of a physical processor. It may be a CPU, a core, or a hyperthread (see [SMT]).
Program Interruption
The idea of multiprogramming technique was conceived when it was realized that precious CPU time was being wasted due to historical programming paradigm. Under History of Operating Systems of [MOS] (Specifically Section 1.2.3), we observe that in the early days of computing, people soon came to realization that I/O wait time accounted for majority of total time for a job to its completion. Instead of providing one job to the CPU at a time, there was a need to allow multiple jobs to exist simultaneously. This would ensure that the CPU is as efficient as possible. Since then, various studies have been done to make the CPU as efficient as it can be.
Preemptive Scheduling
It is the Operating Sytem that is responsible to schedule multiple jobs that are present to be processed. More precisely, the scheduling subsystem (or the scheduler) is responsible for providing CPU time to all threads in the system. In non-preemptive scheduling approach, a job is executed till its completion, and the next one is selected. In contrast, a preemptive scheduling approach, the scheduler is responsible for interrupting the current job (and saving its current state if its not finished) and loading appropriate context for another job in the CPU. Most kernels used in general purpose computers use preemptive schedulers so as to allow multiple jobs to be run.
Preemption is one form of interruption. When there are multiple jobs in a system--as is in most general purpose system--at any given time, some technique is used to ensure that those jobs get their fair share of processing time. A scheduler is a subsystem which is used to achieve this. The frequency at which the kernel will preempt threads, also known as preemption rate, can be fetched using the sysctl(1) utility as:
$ sysctl kern.clockrate
kern.clockrate: { hz = 100, tick = 10000, tickadj = 0, profhz = 100, stathz = 100 }
I might use the term job and thread to imply the same thing. Since a task is not a runnable entity, it cannot be loaded on the processor, but a thread corresponding to a task is loaded on the processor.
Unlike some other system information, the clockrate information is represented as a structure object. The structure defintion can be located in sys/time.h as:
/*
* Getkerninfo clock information structure
*/
struct clockinfo {
int hz; /* clock frequency */
int tick; /* micro-seconds per hz tick */
int tickadj; /* clock skew rate for adjtime() */
int stathz; /* statistics clock frequency */
int profhz; /* profiling clock frequency */
};
Notice that the preemption rate is 100 HZ on my machine. This implies that the timeslice quantum--amount of time a thread receives to use the processor--on my machine is 0.01s (10 ms). The tick value represents the number of microseconds in a scheduler tick. Furthermore, [MOSX_INTERNALS] mentions that hz value can be seen as the frequency of a hardware-independent system clock.
The scheduler on XNU is priority-based. It means that threads (and tasks too) structure contains an attribute that represents its priority. Furthermore, direct alteration of priority is not really
Run Queues
On Mach, a data structure which is non-trivial to the scheduling subsystem is a run queue.
Continuation
Continuation is one of available abstraction which is relevant in context of Mach threads, as mentioned in 7.2.6 of [MOSX_INTERNALS]. It is a facility that allows a (blocking) thread to either use the process model or the interrupt model; two models that operating systems has been using for kernel execution.
A process model is one where the kernel maintains a stack for every thread, i.e., a dedicated kernel stack is used to track the execution state of the thread. On the other hand, an interrupt model is one where the kernel stack is a per-processor resources, instead of the per-thread resource that process model describes. [Draves 91] states the following under Restructuring With Continuations (Section 1.4):
We have restructured the Mach kernel so that a thread can use either the process model or the interrupt model when blocking. When a thread blocks using the process model, its current execution state is recorded on the stack. The blocked thread is resumed with a context-switch. When a thread blocks using the interrupt model, it records the execution context in which it should be resumed in an auxiliary data structure, called a continuation.
Before Mach 3 was introduced, it was limited to process model. Tho process model has the advantage that it can be easily programmed, yet it did come with its drawbacks. The obvious one is the fact that it consumes more space since each thread allocates a stack in the kernel address space (per-thread resource). Another one discussed is that optimization techniques to reduce latency of transferring control from one thread to another was found to be difficult as the kernel stack reflects the state of the blocked thread at the machine level. Furthermore, [Draves 91]--under Some Inadequate Solutions (Section 1.3)--also mentions that interrupt model was inappropriate for the Mach kernel. This is why continuation is considered as the appropriate middle-ground between these two execution models.
It might be helpful to assume we're working on some low level task and not the typical BSD process. Doing so allows us to view instructions without added complexity such as system call transition from user-land to kernel-land, or other hardware/software exceptions. Although they too use the idea of continuation, let's look at a simpler example. Converting the Kernel to Use Continuations (Section 2.2) of [Draves 91] discusses a practical use of continuation:
For threads that run only in the kernel, there is no "return-to-user-level" continuation. In practice, most of our kernel threads execute an infinite loop, blocking until an event occurs, doing some work, and then blocking again. For these threads, we define the continuation to be a function containing the body of the loop. The last statement in the function blocks with a continuation that is the function itself, thereby achieving the infinite loop via tail-recursion.
The reason our previous assumption would be helpful is the fact that we only have to deal with one stack; the kernel stack. Since it's all machine instructions at hardware layer, and we can ease out the illustration by only focusing on one stack. The type definition of a thread continuation function signature is described in [osfmk/kern/kern_types.h].
A pseudo-code representation would look something as follows:
/*
* When the thread resumes later--and since we're using the continuation
* function--a new kernel stack is assigned to the thread where the
* continuation function is executed. The continuation function on
* mach returns nothing and takes two arguments; param and ret.
*
* We won't use the arguments to the continuation function. If we were
* to use it, the 'thread' structure contains a member that holds the
* parameter so that when the thread resumes, the argument can be obtained
* from the 'thread' structure into appropriate register and then
* invoke the continuation function.
*/
typedef int wait_result_t;
typedef void (*thread_continue_t) (void *param, wait_result_t wres);
void
handle_foovent (void)
{
static int start;
/*
* If we're entering this routine for the first time, simply jump to blocking
* the thread with continutation function.
*/
if (start == 0) {
++start;
goto tail;
}
/*
* Local variables can be declared here and be operated on. Recall
* that local variables are stored on the stack, so it will cease
* to exist once we reach the tail of this function.
*
* If you must have persistant storage, define global or static
* variables such that they take allocate space on the DATA section.
*/
...
/* Handle the event accordingly */
...
tail:
/*
* block the thread--yielding the processor to other thread and
* "sleeping" till some event occurs; essentially changing the
* process state--with the hypothetical thread_block() function.
* For the sake of brevity, we'll just assume that it only requires
* one argument and that is the pointer to the continuation function.
* If it is NULL, it asserts that preservation of the stack (the only
* stack in our example; as it is just a Mach thread with no BSD
* process association) must happen, and also continue after this
* thread_block() function.
*
* If the argument is a valid pointer, the behavior is slightly different.
* We now assert this thread to wait for some event to occur, and after it
* does, jump to the function pointed by the address. It also conveys that
* the stack used for this thread can now be deallocated (freed up) or given
* to some other thread.
*
* Once this thread resumes, handle_foovent will be called, thereby achieving
* recursion. But since the stack is not preserved, each invokation of
* 'handle_foovent' will have only one stack to work with on the call stack.
*/
thread_block(handle_foovent);
/*NOTREACHED*/
}
On XNU, there are two function definition of our interest regarding thread blocking: thread_block defined in [osfmk/kern/sched_prim.c] and thread_block_parameter defined in the same file, [osfmk/kern/sched_prim.c]. Both of these functions internally calls thread_block_reason defined in the same file [osfmk/kern/sched_prim.c]. Like stated above, the parameter to the continuation function is optional. If it must be provided, thread_block_parameter must be used and struct thread's member parameter will hold this value and load it into appropriate register before calling the continuation function.
On thread_block_reason function, we see the following block:
do {
thread_lock(self);
new_thread = thread_select(self, processor, &reason);
thread_unlock(self);
} while (!thread_invoke(self, new_thread, reason));
thread_lock and thread_unlock
thread_lock and thread_unlockThe functions thread_lock and thread_unlock are essentially macros that expand to functions (a function is a closed subroutine, whereas a macro is an open subroutine). These are defined as parameterized macros in [osfmk/kern/thread.h] as:
#define thread_lock(th) simple_lock(&(th)->sched_lock, &thread_lck_grp)
#define thread_unlock(th) simple_unlock(&(th)->sched_lock)
Mach uses simple locks to protect most of the kernel data structures. There are three flavors of spinlocks: hw_lock (hw_lock_t [osfmk/kern/lock_types.h]), usimple (usimple_lock_t (i386) [osfmk/i386/simple_lock.h] and usimple_lock_t (arm) [osfmk/arm/simple_lock.h]), and simple (lck_spin_t (i386) [osfmk/i386/locks.h] and lck_spin_t (arm) [osfmk/arm/locks.h]). Only the last one is exported to loadable kernel extensions. Below is an excerpt from [MOSX_INTERNALS] (Section 9.18.2.1) that describes the spinlock behavior in uniprocessor and multiprocessor systems:
Moreover, the use of a spinlock is different on a multiprocessor system compared with a uniprocessor system. On the former, a thread could busy-wait on one processor while the holder of a spinlock uses the protected resources on another processor. On a uniprocessor, a tight loop--if not preempted--will spin forever, since the holder of the lock will never get a chance to run and free the task!
One of the reason for the implementation of usimple lock was to support true spin lock mechanism on uniprocessor system. On Spinlocks subsection of Synchronization Primitives Chapter, we notice that traditional simple locks--while disabling preemption--do not spin on uniprocessor systems. [MOSX_INTERNALS] mentions that simple lock "disappears" on a uniprocessor system. Furthermore, once a usimple lock is acquired, preemption is disabled, and is again re-enabled once the lock is released.
Getting back, it also appears that simple_lock too is a macro... and it's architecture dependent. In ARM variant, the macro simple_lock is defined in [osfmk/arm/simple_lock.h] and we see that the macro conditionally expands based on whether or not the symbol LCK_GRP_USE_ARG is defined (and is not 0):
#define simple_lock_init(l, t) arm_usimple_lock_init(l,t)
#if LCK_GRP_USE_ARG
#define simple_lock(l, grp) lck_spin_lock_grp(l, grp)
...
#else
#define simple_lock(l, grp) lck_spin_lock(l)
...
#endif /* LCK_GRP_USE_ARG */
#define simple_unlock(l) lck_spin_unlock(l)
And the general macro can be found in [osfmk/kern/simple_lock.h] when the macro simple_lock_init is not defined:
/*
* If we got to here and we still don't have simple_lock_init
* defined, then we must either be outside the osfmk component,
* running on a true SMP, or need debug.
*/
#if !defined(simple_lock_init)
#define simple_lock_init(l, t) usimple_lock_init(l,t)
#define simple_lock(l, grp) usimple_lock(l, grp)
#define simple_unlock(l) usimple_unlock(l)
...
#endif /* !defined(simple_lock_init) */
The definition of usimple_lock (for i386) is defined in [osfmk/i386/locks_i386.c], and so is usimple_unlock defined in [osfmk/i386/locks_i386.c].
I should also mention that [osfmk/i386/locks_i386.c] also defines the functions: lck_spin_lock_grp and lck_spin_lock, but they internally call the function usimple_lock.
For the ARM variant, the function is defined in [osfmk/arm/locks_arm.c]. We see that it internally calls a function lck_spin_verify that is defined in the same file as:
#if DEVELOPMENT || DEBUG
...
static inline void
lck_spin_verify(lck_spin_t *lck)
{
if (lck->type != LCK_SPIN_TYPE ||
lck->lck_spin_data == LCK_SPIN_TAG_DESTROYED) {
__lck_spin_invalid_panic(lck);
}
}
#else /* DEVELOPMENT || DEBUG */
#define lck_spin_verify(lck) ((void) 0)
#endif /* DEVELOPMENT || DEBUG */
Recall that thread_block_reason forces a reschedule.
Although mentioned about it in user threads section, Mach threads also contains attribute regarding continuation. On [osfmk/mach/arm/vm_param.h], we see the symbol KERNEL_STACK_SIZE being defined as:
#if KASAN
/* Increase the stack sizes to account for the redzones that get added to every
* stack object. */
# define KERNEL_STACK_SIZE (4*4*4096)
#elif DEBUG
/**
* Increase the stack size to account for less efficient use of stack space when
* compiling with -O0.
*/
# define KERNEL_STACK_SIZE (2*4*4096)
#else
/*
* KERNEL_STACK_MULTIPLIER can be defined externally to get a larger
* kernel stack size. For example, adding "-DKERNEL_STACK_MULTIPLIER=2"
* helps avoid kernel stack overflows when compiling with "-O0".
*/
#ifndef KERNEL_STACK_MULTIPLIER
#define KERNEL_STACK_MULTIPLIER (1)
#endif /* KERNEL_STACK_MULTIPLIER */
# define KERNEL_STACK_SIZE (4*4096*KERNEL_STACK_MULTIPLIER)
#endif /* XNU_KERNEL_PRIVATE */
Here, we see that the kernel stack must be at least 16 KB and could also be changed for a program when compiling. We know that a user thread has its corresponding Mach thread. Although there exists some operating system which multiplexes multiple user threads to a single kernel thread (Mach thread is essentially a kernel thread), it has some drawbacks. One of them is the fact that the user threads cannot be scheduled independently of each other, resulting in loss of concurrency.
Further Reading
[MICRO_MONO_KERN] Despite their differences, many authors agree that the theoretical architectures often mislead the actual implementation. For example, although Linux is a monolithic kernel, subsystem like eBPF allow the user to program the kernel, thereby allowing the property of a micro kernel. XNU--an open source kernel from Apple--can be considered as a monolithic kernel since the kernel task, a single task (with multiple threads), performs operation such as scheduling, thread reaping, callout management, paging, and UNIX exception handling. It can be considered as a monolithic kernel with different components such as Mach, BSD, and the I/O kit, all running as groups of threads in a single task in the same address space.
[BSD_ON_MACH] Although one might assume that Mach kernel is BSD-like kernel, it is not entirely correct. The BSD kernel found in OS X implementation is based upon FreeBSD. The Kernel Architecture Overview chapter illustrates the OS X architecture. We can observe that the BSD layer is built on top of the Mach kernel. In fact, a BSD process is one which has a corresponding Mach task assigned to it, but not all Mach task are required to have a BSD process.
[MD_THREAD_CTX] For ARM variant, the type arm_context_t is defined as typedef struct arm_context arm_context_t; and this structure inturn contains another structure member as struct arm_saved_state ss; along with another structure member for arm neon state (which we won't look into). struct arm_saved_state contains a union member as union { struct arm_saved_state32; struct arm_saved_state64; } uss;. When we look into any of the structure declared within the union, we observe that it contains information such as the array of general purpose registers, "special" registers such as the stack pointer, frame pointer, and such.
[PROC_SIGACTS] On [bsd/sys/proc_internal.h], we see the definition of the structure as:
/*
* Process signal actions and state, needed only within the process
* (not necessarily resident).
*/
struct sigacts {
user_addr_t ps_sigact[NSIG]; /* disposition of signals */
user_addr_t ps_trampact[NSIG]; /* disposition of signals */
sigset_t ps_catchmask[NSIG]; /* signals to be blocked */
sigset_t ps_sigonstack; /* signals to take on sigstack */
sigset_t ps_sigintr; /* signals that interrupt syscalls */
sigset_t ps_sigreset; /* signals that reset when caught */
sigset_t ps_signodefer; /* signals not masked while handled */
sigset_t ps_siginfo; /* signals that want SA_SIGINFO args */
sigset_t ps_oldmask; /* saved mask from before sigpause */
_Atomic uint32_t ps_sigreturn_validation; /* sigreturn argument validation state */
int ps_flags; /* signal flags, below */
int ps_sig; /* for core dump/debugger XXX */
int ps_code; /* for core dump/debugger XXX */
int ps_addr; /* for core dump/debugger XXX */
};
The comment suggests that signal action structure of a process may not always exist on the main memory and can be swapped if memory contention exists.
Recall that a BSD layer exists above the Mach kernel. Signals are BSD (well, UNIX specifically) property and not of Mach. On Mach-level--akin to low level programming--exceptions exists which may have corresponding signals on BSD process context. An example of this would be the classic segment violation (SIGSEGV) signal. This signal is generated when an attempt is made to dereference an address that is invalid for the process. When the corresponding assembly instruction is executed, EXC_BAD_ACCESS exception is generated on the Mach layer, and is translated to the respective signal for the process over the Mach layer.
Lastly, if you're wondering how the translation of a Mach exception to BSD signal is done, there exists a function ux_exception found in [bsd/uxkern/ux_exception.c].
[CORE] The term core has various meaning depending on the context. As can be seen from a different perspective, section 3.9 of [APUE] has the following statement:
The term incore means in main memory. Back in the day, a computer's main memory was built out of ferrite core. This is where the phrase "core dump" comes from: the main memory image of a program is stored in a file on disk for diagnosis.
In regards to processors, a core refers to an individual processing unit within computing system. On a uniprocessor system, there exist only one core which is responsible for processing the instructions. Parallel computing is not possible but concurrency strategies can be applied on such systems. In contrast, a multiprocessor system is one where multiple cores are present and various strategies can be used to achieve true parallelism.
A multi-core processor is a microprocessor with two or more separate processing units on a single integrated circuit. Conversely, a multi-CPU system contains two or more distinct integrated circuits (often referred to as dies or silicons) installed on the motherboard.
Hence, a multiprocessor system can be made by either: using multiple physical CPU chips (multi-CPU system), or using a single chip with multiple processing units (multi-core system).
There are two popular strategies for a multiprocessing system: Symmetric Multi-Processing (SMP) and Asymmetric Multi-Processing (AMP or ASMP). SMP-based systems are such where all cores are treated equally. Figure 2, which is an excerpt from Wikipedia: Symmetric multiprocessing, shows a high-level overview of a symmetric multiprocessor system. Typically, cores on a SMP-based systems share components such as global memory (main memory), disks, I/O devices, and interrupt system. Notice that each processor has an associated cache, which is present to speed up the main memory data access and to also reduce the traffic on system bus.
Given that multiple processors share the same main memory, access to the main memory must be in serial order; serialization must take place. To mitigate such performance bottlenecks, newer memory designs such as NUMA are proposed which allows each processor to contain its own dedicated memory bank. On NUMA-based architecture, access to local memory (e.g. a portion of the main memory) is significantly faster as compared to traditional SMP where entire main memory is shared. It does come with its own drawback, tho. One in particular is the fact that access to non-local (or remote; portion of main memory which is not assigned to the processor) memory is expensive.

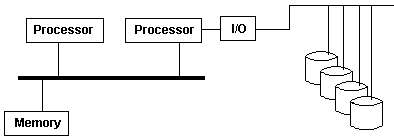
On the other hand, AMP-based systems do not treat all cores as the same. For example, a system could contain multiple cores but only one core is present to execute the instructions while other cores are present to handle I/O operations. Figure 3 (excerpt from Wikipedia: Asymmetric multiprocessing) shows a high-level architecture view of Asymmetric multiprocessing.
From the computing environment standpoint (see [INTEL_HVHCE]), SMP is identical to Homogeneous Computing, wherein all processing units are of the same type and have similar capabilities. AMP, in contrast, is similar to Heterogeneous Computing. Such computing environment involves a system that comprise of different processing units such as Central Processing Units (CPUs), Graphics Processing Units (GPUs), Field-Programmable Gate Arrays (FPGAs), or specialized accelerators.
[SMT] Before briefly describing about Simultaneous MultiThreading (SMT) and Intel's implemention of it; also known as Hyper-Threading Technology (HTT), let's first understand some basic concepts. A scalar processor is class of computer processor which is able to process only one data item at a time. Based on Flynn's taxonomy, a scalar processor is classified as a Single Instruction, Single Data (SISD) processor. Another class of computer processor exists which operates on multiple data through a single instruction. Such processors--which is also known as Single Instruction, Multiple Data (SIMD)--are classified as vector processor.
The superscalar processor, which can be thought of as mixture of scalar and vector processor, has instructions which operate on one data item but such processor contains multiple execution units which allows execution of more than one instruction during a clock cycle. An execution unit (E-unit or EU) is a part of processing unit that performs the operations and calculations forwarded from the instruction unit (I-unit or IU). The sequnce to process an instruction can be as simple as one mentioned below (classic RISC pipeline):
- Instruction Fetch (IF): Retrieve the instruction from memory.
- Instruction Decode (ID): Decode instruction to know the instruction class, opcodes, operands of the instruction.
- Execute (E): Execute the instruciton.
- Memory Access (MA): Read or write back to main memory (for some instructions).
- Write Back (WB): Save the result back to register.
IU is responsible for handling the IF and ID steps of pipeline, whereas EU is responsible for the rest of the pipeline steps. It should be noted that superscalar and pipeline are two different performance improvement techniques. Wikipedia: Superscalar processor contains the following paragraph:
The former (superscalar) executes multiple instructions in parallel by using multiple execution units, whereas the latter (pipeline) executes multiple instructions in the same execution unit in parallel by dividing the execution unit into different phases.
One might wonder how come a single execution unit can execute multiple instructions in parallel. It is possible by virtue of many internal units within a single execution unit. Some of the internal units commonly found are (see Wikipedia: Central processing unit (Instruction-level parallelism)): load-store units, arithmetic-logic units, floating-point units, and address-generation units.
SMT is a technique used for improving the overall efficiency of superscalar CPUs with hardware multithreading. Two major implementation of multithreading can be done: SMT and temporal multithreading. The major difference between these two is the fact that temporal multithreading limits only one thread's instructions in a pipeline at a time. On SMT-based superscaler CPUs, instructions from more than one thread can be executed in any given pipeline stage at a time.
HTT is Intel's proprietary SMT implementation used to improve parallelization of computations performed on x86 microprocessors. For each processor core that is physically present, the operating system addresses two virtual (logical) cores and shares the workload between them when possible. Doing so allows concurrent scheduling of two processes per core.
Signals
Signals act as a notification system for a process. Similar to how executing some instruction might invoke an exception (such as divide by 0 condition or segmentation violation), we can think of signals as mechanism to provide notification for exceptional condition. It's not limited to hardware exceptions by any means, and there are plenty of software-based signals we'll explore shortly. Because of this general interface, signals are often known as software interrupts.
A process can inform the kernel to do one of three things when a signal occurs, which will be discussed shortly. Such phenomena is often referred to as disposition of signal, or action associated with the signal. Although the kill(1) command sounds like a misnomer, it was introduced of yore when signals were mostly seen as a means to handle misbehaving process. Since then, signals have evolved vastly, allowing a new form of programming; event driven. We won't delve this new form of programming for now, as it can cover a topic of its own.
Like mentioned earlier, one of three possible disposition of signals are:
-
Ignore the signal. Note that the kernel still needs a way to kill a process, necessitating two signals to be unignored (and uncatchable): SIGKILL and SIGSTOP.
-
Default action for the signal.
-
Installing a handler for the signal.
XNU Implementation
This section documents some of the implementation found in the XNU source tree.
1. [XNU_PTRAUTH_SIGNED_PTR] In the source, we see the field declared as:
struct task {
...
vm_map_t XNU_PTRAUTH_SIGNED_PTR("task.map") map;
...
}
The arm64e specification introduced the notion of Pointer Authentication Code. Various articles are available on the web which explains this topic. If you want to explore it, Pointer Authentication documentation from clang explains this topic in an apparent manner. Getting back, XNU_PTRAUTH_SIGNED_PTR is a macro which is defined (in [libkern/os/bash.h]) as:
#if KERNEL
#if __has_feature(ptrauth_calls)
#define XNU_PTRAUTH_SIGNED_FUNCTION_PTR(type) \
__ptrauth(ptrauth_key_function_pointer, 1, ptrauth_string_discriminator(type))
#else
#define XNU_PTRAUTH_SIGNED_FUNCTION_PTR(type)
#endif
#define XNU_PTRAUTH_SIGNED_PTR OS_PTRAUTH_SIGNED_PTR
#define XNU_PTRAUTH_SIGNED_PTR_AUTH_NULL OS_PTRAUTH_SIGNED_PTR_AUTH_NULL
#endif // KERNEL
The macro OS_PTRAUTH_SIGNED_PTR is also defined under the same file, [libkern/os/bash.h], as:
#if KERNEL
#if __has_feature(ptrauth_calls)
#include <ptrauth.h>
#define OS_PTRAUTH_SIGNED_PTR(type) __ptrauth(ptrauth_key_process_independent_data, 1, ptrauth_string_discriminator(type))
#define OS_PTRAUTH_SIGNED_PTR_AUTH_NULL(type) __ptrauth(ptrauth_key_process_independent_data, 1, ptrauth_string_discriminator(type), "authenticates-null-values")
#define OS_PTRAUTH_DISCRIMINATOR(str) ptrauth_string_discriminator(str)
#define __ptrauth_only
#else // __has_feature(ptrauth_calls)
#define OS_PTRAUTH_SIGNED_PTR(type)
#define OS_PTRAUTH_SIGNED_PTR_AUTH_NULL(type)
#define OS_PTRAUTH_DISCRIMINATOR(str) 0
#define __ptrauth_only __unused
#endif // __has_feature(ptrauth_calls)
#endif // KERNEL
2. [AST_ENUM_OPT_DECL] In the source, we see the field declared as: os_atomic(ast_t) ast;. os_atomic is a parameterized macro that expands conditionally. In [libkern/os/atomic.h], there are two (conditional) macro definitions for os_atomic. From what I can tell, if C++ is used, it is defined as: #define os_atomic(type) std::atomic<type> volatile, and otherwise defined as: #define os_atomic(type) type volatile _Atomic.
Besides that, ast_t is an enumerable type, defined (in [osfmk/kern/ast.h]) as:
__options_decl(ast_t, uint32_t, {
AST_PREEMPT = 0x01,
AST_QUANTUM = 0x02,
AST_URGENT = 0x04,
AST_HANDOFF = 0x08,
AST_YIELD = 0x10,
AST_APC = 0x20, /* migration APC hook */
AST_LEDGER = 0x40,
AST_BSD = 0x80,
AST_KPERF = 0x100, /* kernel profiling */
AST_MACF = 0x200, /* MACF user ret pending */
AST_RESET_PCS = 0x400, /* restartable ranges */
AST_ARCADE = 0x800, /* arcade subsciption support */
AST_MACH_EXCEPTION = 0x1000,
AST_TELEMETRY_USER = 0x2000, /* telemetry sample requested on interrupt from userspace */
AST_TELEMETRY_KERNEL = 0x4000, /* telemetry sample requested on interrupt from kernel */
AST_TELEMETRY_PMI = 0x8000, /* telemetry sample requested on PMI */
AST_SFI = 0x10000, /* Evaluate if SFI wait is needed before return to userspace */
AST_DTRACE = 0x20000,
AST_TELEMETRY_IO = 0x40000, /* telemetry sample requested for I/O */
AST_KEVENT = 0x80000,
AST_REBALANCE = 0x100000, /* thread context switched due to rebalancing */
// was AST_UNQUIESCE 0x200000
AST_PROC_RESOURCE = 0x400000, /* port space and/or file descriptor table has reached its limits */
AST_DEBUG_ASSERT = 0x800000, /* check debug assertion */
AST_TELEMETRY_MACF = 0x1000000, /* telemetry sample requested by MAC framework */
AST_SYNTHESIZE_MACH = 0x2000000,
});
where __options_decl is a parameterized macro (defined in [bsd/sys/cdefs.h]) which expands as:
#if __has_attribute(enum_extensibility)
#define __enum_open __attribute__((__enum_extensibility__(open)))
#define __enum_closed __attribute__((__enum_extensibility__(closed)))
#else
#define __enum_open
#define __enum_closed
#endif // __has_attribute(enum_extensibility)
#if __has_attribute(flag_enum)
#define __enum_options __attribute__((__flag_enum__))
#else
#define __enum_options
#endif
#define __options_decl(_name, _type, ...) \
typedef enum : _type __VA_ARGS__ __enum_open __enum_options _name
The internal type used for an enumeration type is an integer. It is implementation defined whether the integer is signed or unsigned. Moreover, the width of the integer is usually that of int data type.
If we want to override the default implementation of the enumeration type (like shown above), the syntax would be:
enum : unsigned int {
FOO,
BAR,
BAZ
};
This is not defined in the C standard, but most compilers for the C language supports this extension for an enumeration type.
3. [LIST_ENTRY] The macro used, LIST_ENTRY, is defined under [bsd/sys/queue.h] as:
#define LIST_ENTRY(type) \
__MISMATCH_TAGS_PUSH \
__NULLABILITY_COMPLETENESS_PUSH \
struct { \
struct type *le_next; /* next element */ \
struct type **le_prev; /* address of previous next element */ \
} \
__NULLABILITY_COMPLETENESS_POP \
__MISMATCH_TAGS_POP
Although not needed, __MISMATCH_TAGS_PUSH and __MISMATCH_TAGS_POP expands to pragma operators for C++ (and when using clang(1) compiler), else to nothing. These macros too are defined in [bsd/sys/queue.h] with definition as:
#if defined(__clang__) && defined(__cplusplus)
#define __MISMATCH_TAGS_PUSH \
_Pragma("clang diagnostic push") \
_Pragma("clang diagnostic ignored \"-Wmismatched-tags\"")
#define __MISMATCH_TAGS_POP \
_Pragma("clang diagnostic pop")
#else
#define __MISMATCH_TAGS_PUSH
#define __MISMATCH_TAGS_POP
#endif
Likewise, __NULLABILITY_COMPLETENESS_PUSH and __NULLABILITY_COMPLETENESS_POP only expand to pragma when compiling with clang. It is also defined in [bsd/sys/queue.h]. The definition is as follows:
#if defined(__clang__)
#define __NULLABILITY_COMPLETENESS_PUSH \
_Pragma("clang diagnostic push") \
_Pragma("clang diagnostic ignored \"-Wnullability-completeness\"")
#define __NULLABILITY_COMPLETENESS_POP \
_Pragma("clang diagnostic pop")
#else
#define __NULLABILITY_COMPLETENESS_PUSH
#define __NULLABILITY_COMPLETENESS_POP
#endif
4. [TAILQ_ENTRY] The macro TAILQ_ENTRY is defined in [bsd/sys/queue.h] as:
#define TRACEBUF struct qm_trace trace;
#define TAILQ_ENTRY(type) \
__MISMATCH_TAGS_PUSH \
__NULLABILITY_COMPLETENESS_PUSH \
struct { \
struct type *tqe_next; /* next element */ \
struct type **tqe_prev; /* address of previous next element */ \
TRACEBUF \
} \
__NULLABILITY_COMPLETENESS_POP \
__MISMATCH_TAGS_POP
Except for the presence of another macro: TRACEBUF, it is similar to one described in [LIST_ENTRY].
Mach Routines
The description of most of these routines can be found in MIT: Mach IPC Interface
-
mach_task_self: Return a send right to the caller's task_self port.#include <mach/mach_traps.h>
/*
* param: none
*
* return: send right to the task's kernel port.
*/
mach_port_t
mach_task_self (void);cautionUnder
mach/mach_init.hfile, we see the declaration ofmach_task_selfas:extern mach_port_t mach_task_self_;
#define mach_task_self() mach_task_self_
#define current_task() mach_task_self() -
task_info: Return per-task information according to specified flavor.#include <mach/task.h>
/*
* params:
* task - The port of the task for which the information is to be returned.
* flavor - The type of information to be returned. See below.
* task_info - Information about the specified task.
* task_info_count - On input, the maximum size of the buffer; on output, the size returned (in natural-sized units).
*/
kern_return_t
task_info ( task_t task,
task_flavor_t flavor,
task_info_t task_info,
mach_msg_type_number_t task_info_count);The table below describes the various arguments to flavor, task_info, and task_info_count which is currently implemented in XNU (specifically [osfmk/kern/task.c]).
flavor task_info (address of) task_info_count Remark TASK_BASIC_INFO_32 struct task_basic_info_32 (task_basic_info_32_data_t) TASK_BASIC_INFO_32_COUNT Not preferred; use MACH_TASK_BASIC_INFO TASK_BASIC2_INFO_32 struct task_basic_info_32 (task_basic_info_32_data_t) TASK_BASIC_INFO_32_COUNT Not preferred; BASIC2 was used to get the maximum resident size instead of current resident size TASK_BASIC_INFO_64 struct task_basic_info_32 (task_basic_info_32_data_t) TASK_BASIC_INFO_32_COUNT Not preferred; only available on arm64 (non-arm64 described below) TASK_BASIC_INFO_64 struct task_basic_info_64 (task_basic_info_64_data_t) TASK_BASIC_INFO_64_COUNT Not preferred; used on non-arm64 variant TASK_BASIC_INFO_64_2 struct task_basic_info_64_2 (task_basic_info_64_2_data_t) TASK_BASIC_INFO_64_2_COUNT Not preferred; only available on arm64 MACH_TASK_BASIC_INFO struct mach_task_basic_info (mach_task_basic_info_data_t) MACH_TASK_BASIC_INFO_COUNT - TASK_THREAD_TIMES_INFO struct task_thread_times_info (task_thread_times_info_data_t) TASK_THREAD_TIMES_INFO_COUNT - TASK_ABSOLUTETIME_INFO struct task_absolutetime_info (task_absolutetime_info_data_t) TASK_ABSOLUTETIME_INFO_COUNT - TASK_DYLD_INFO struct task_dyld_info (task_dyld_info_data_t) TASK_DYLD_INFO_COUNT After the addition of all_image_info_formatfield,task_info_countcould be either TASK_DYLD_INFO_COUNT or the backward compatible TASK_LEGACY_DYLD_INFO_COUNTTASK_EXTMOD_INFO struct task_extmod_info (task_extmod_info_data_t) TASK_EXTMOD_INFO_COUNT - TASK_KERNELMEMORY_INFO struct task_kernelmemory_info (task_kernelmemory_info_data_t) TASK_KERNELMEMORY_INFO_COUNT - TASK_SCHED_FIFO_INFO struct policy_fifo_base (policy_fifo_base_data_t) POLICY_FIFO_BASE_COUNT Obsolete; see below TASK_SCHED_RR_INFO struct policy_rr_base (policy_rr_base_data_t) POLICY_RR_BASE_COUNT Obsolete; see below TASK_SCHED_TIMESHARE_INFO struct policy_timeshare_base (policy_timeshare_base_data_t) POLICY_TIMESHARE_BASE_COUNT Obsolete; see below TASK_SECURITY_TOKEN security_token_t (defined in mach/message.h)TASK_SECURITY_TOKEN_COUNT - TASK_AUDIT_TOKEN audit_token_t (defined in mach/message.h)TASK_AUDIT_TOKEN_COUNT - TASK_SCHED_INFO - - Obsolete TASK_EVENTS_INFO struct task_events_info (task_events_info_data_t) TASK_EVENTS_INFO_COUNT - TASK_AFFINITY_TAG_INFO struct task_affinity_tag_info (task_affinity_tag_info_data_t) TASK_AFFINITY_TAG_INFO_COUNT On task_info implementation of XNU, it appears to internally call task_affinity_infowhich is defined in [osfmk/kern/affinity.c]TASK_POWER_INFO struct task_power_info (task_power_info_data_t) TASK_POWER_INFO_COUNT On task_info implementation of XNU, it appears to internally call task_power_info_lockedwhich is defined in [osfmk/kern/task.c]TASK_POWER_INFO_V2 struct task_power_info_v2 (task_power_info_v2_data_t) TASK_POWER_INFO_V2_COUNT (or TASK_POWER_INFO_V2_COUNT_OLD) On task_info implementation of XNU, it only checks for TASK_POWER_INFO_V2_COUNT_OLD, and also calls task_power_info_lockedTASK_VM_INFO struct task_vm_info (task_vm_info_data_t) TASK_VM_INFO_COUNT The value of task_info_countcould also beTASK_VM_INFO_REV[0-7]_COUNT, whereTASK_INFO_REV7_COUNTis identical toTASK_VM_INFO_COUNT. The structure definition provides additional attributes for each new revision. Some additional checks is performed on arm64 architecture on Iphones (some apps passtask_info_countas count of bytes instead of count ofnatural_t) ...TASK_VM_INFO_PURGEABLE struct task_vm_info (task_vm_info_data_t) TASK_VM_INFO_COUNT ... and if the task is a kernel task, the internalfield oftask_vm_info_data_tis adjusted by considering the "memory held in VM compressor". Furthermore, whenTASK_VM_INFO_PURGEABLEis used,purgeable_volatile_[pmap|resident|virtual]attributes are appropriately returned. A series of checks for revision is performed and appropriate attributes are filledTASK_WAIT_STATE_INFO struct task_wait_state_info (task_wait_state_info_data_t) TASK_WAIT_STATE_INFO_COUNT Marked as deprecated with further note as, "Currently allowing some results until all users stop calling it. The results may not be accurate." TASK_VM_INFO_PURGEABLE_ACCOUNT struct pvm_account_info (pvm_account_info_data_t) PVM_ACCOUNT_INFO_COUNT Only visible in developement builds ( DEVELOPMENTorDEBUGsymbol must be present while compiling the kernel). ReturnsKERN_NOT_SUPPORTEDwhen used on production buildsTASK_FLAGS_INFO struct task_flags_info (task_flags_info_data_t) TASK_FLAGS_INFO_COUNT - TASK_DEBUG_INFO_INTERNAL struct task_debug_info_internal (task_debug_info_internal_data_t) TASK_DEBUG_INFO_INTERNAL_COUNT Only visible in developement builds ( DEVELOPMENTorDEBUGsymbol must be present while compiling the kernel). ReturnsKERN_NOT_SUPPORTEDwhen used on production buildsTASK_SUSPEND_STATS_INFO struct task_suspend_stats_s (task_suspend_stats_data_t) TASK_SUSPEND_STATS_INFO_COUNT Requires CONFIG_TASK_SUSPEND_STATSsymbol to be present along with either of debug symbol (DEVELOPMENTorDEBUG) when compiling the kernel to support this flavor. ReturnsKERN_NOT_SUPPORTEDwhen used on production buildsTASK_SUSPEND_SOURCES_INFO struct task_suspend_source_s (task_suspend_source_data_t) TASK_SUSPEND_SOURCES_INFO_COUNT Requires CONFIG_TASK_SUSPEND_STATSsymbol to be present along with either of debug symbol (DEVELOPMENTorDEBUG) when compiling the kernel to support this flavor. ReturnsKERN_NOT_SUPPORTEDwhen used on production buildsTASK_SECURITY_CONFIG_INFO struct task_security_config_info TASK_SECURITY_CONFIG_INFO_COUNT - TASK_IPC_SPACE_POLICY_INFO struct task_ipc_space_policy_info TASK_IPC_SPACE_POLICY_INFO_COUNT - dangerRegarding
TASK_SCHED_FIFO_INFO,TASK_SCHED_RR_INFO, andTASK_SCHED_TIMESHARE_INFO, until commit [c1dac77], XNU provided appropriatetask_infohandling capability. However, starting commit [8149afc], support forTASK_SCHED_FIFO_INFOwas removed. Although capability forTASK_SCHED_RR_INFOandTASK_SCHED_TIMESHARE_INFOstill exist, commit [14e3d83] marked them as obsolete.
References
[DEV_APPLE_MACH] https://developer.apple.com/library/archive/documentation/Darwin/Conceptual/KernelProgramming/Mach/Mach.html
[APUE] Stevens, W.R., & Rago. S.A. (2013). Advanced Programming in Unix Environment.
[MOS] Tanenbaum, A.S., & Bos H. (2014). Modern Operating Systems.
[MOSX_INTERNALS] Singh, A (2007). Mac OS X Internals: A Systems Approach.
[OS_INTERNALS] Levin, J (2016, 2017, 2019) MacOS and iOS Internals Trilogy. https://www.newosxbook.com/index.php
[INTEL_HVHCE] https://www.intel.com/content/www/us/en/docs/sycl/introduction/latest/01-homogeneous-vs-heterogeneous.html
[XNU_GIT] https://github.com/apple-oss-distributions/xnu
[Draves 91] http://staff.ustc.edu.cn/~bjhua/courses/ats/2014/ref/draves91continuations.pdf
[COMMIT] f6217f891ac0bb64f3d375211650a4c1ff8ca1ea